There’s a new software reliability conference that just spun up called Software Should Work, and I had a chance to give a talk there. I took the opportunity to speak about one of my favorite topics: saturation. Here’s a recording of it..
Synthesis is harder than analysis
Over the years, mathematicians, logicians and computer scientists have developed various calculi. If you have a background in computer science, you’ve likely heard of the lambda calculus, a model of computation that was developed by Alonzo Church. If databases are more your thing, then you’ve been exposed to the relational calculus without even knowing it, since SQL is based on the relational calculus. If you are into formal methods, then you’ve worked with the predicate calculus, better known as first-order logic. Finally, if you enjoy reading academic papers on programming languages, you’ve almost certainly run into the sequent calculus. However, when someone says “calculus” without modification (e.g., “I’m taking calculus next semester”), there’s no ambiguity about which calculus they are referring to: it’s always one particular calculus. Or, rather, two calculi that happen to be deeply related to each other: differential calculus and integral calculus.
Visually, you can think of differential calculus as being about calculating the slope of a function at a given point. For example, consider this graph:
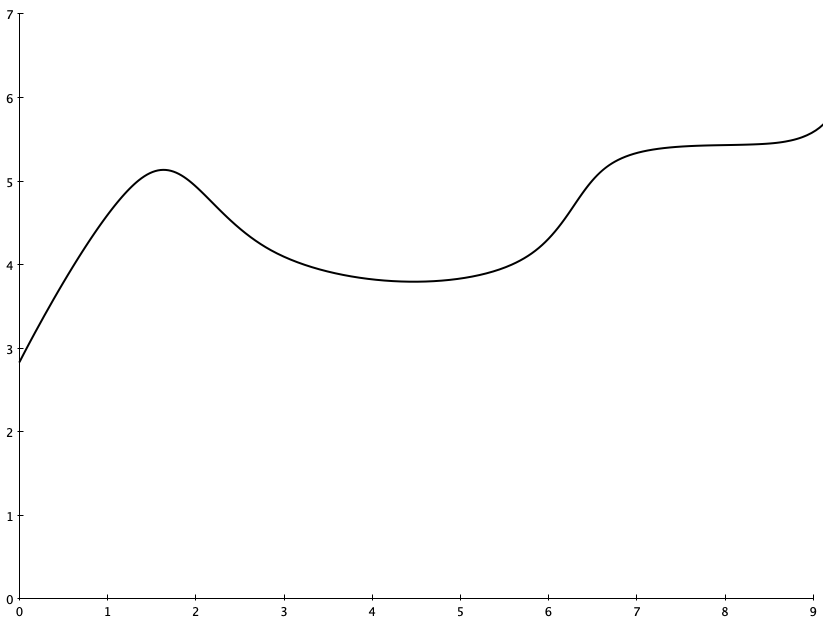
You might ask, “how quickly is this curve changing when x=6?” In other words, what is the slope of this function right in a neighborhood very close to x=6?
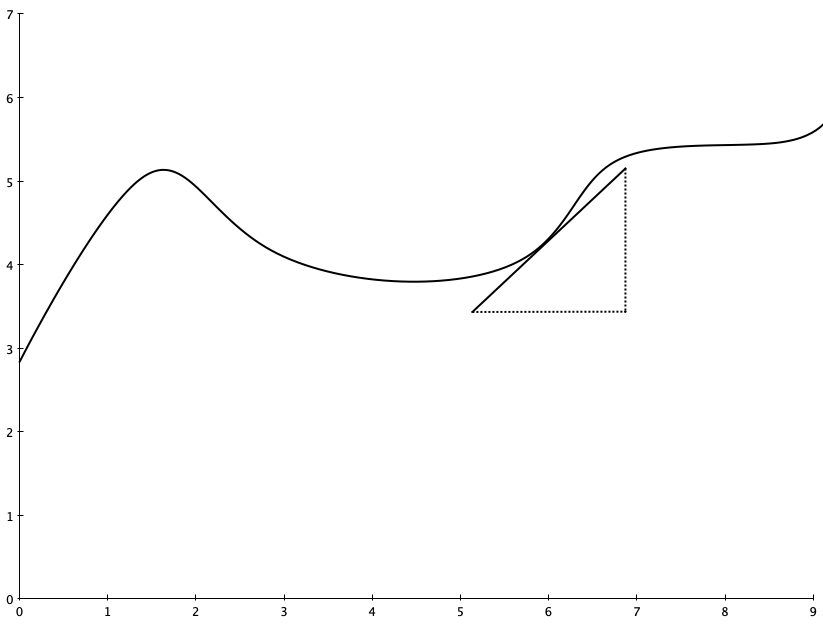
Integral calculus, on the other hand, is about the area under the graph over a particular interval. For example, you might ask “what is the area under this curve between x=2 and x=7?
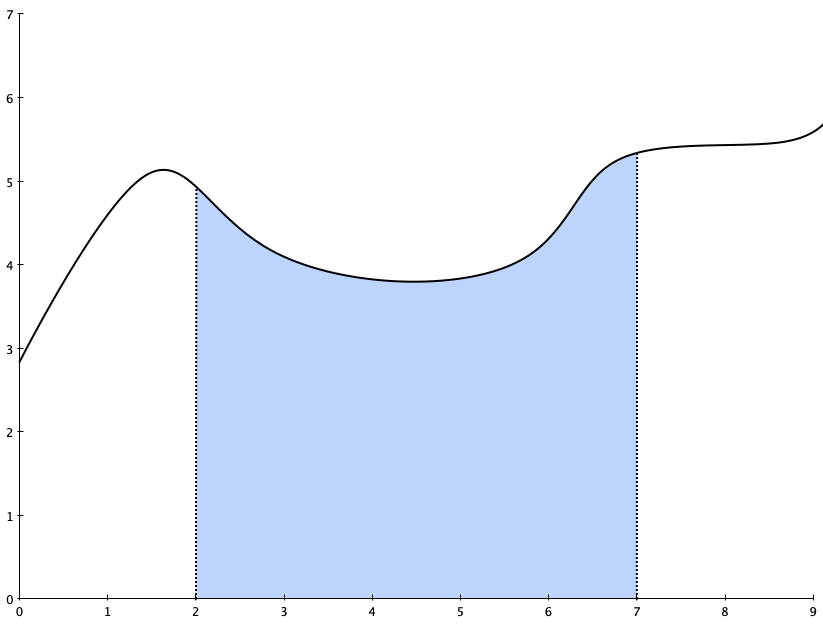
If you study calculus, you’ll first be taught differential calculus (sometimes referred to “Calculus 1” or “Cal 1”) and then you’ll be taught integral calculus (“Cal 2”). When you study differential calculus, you learn the rules for calculating the derivative (slope-at-a-point) of a function. And it turns out that it’s quite straightforward to calculate a derivative, no matter what type of function it is. It’s just an algorithm, which means you can easily program a computer to compute derivatives if you wanted to. (As an aside, automatically computing derivatives is a fundamental element in the process of training LLMs. If you’re curious, look up automatic differentiation).
And then, you get to Cal 2, and you learn about how to compute an integral (area-under-a-curve). You will soon discover that, unlike in Cal 1, there is no algorithm for computing the integral of an arbitrary function. Instead, what you learn is a bag of tricks on how to compute integrals for different kinds of functions. You also learn that for some functions, there’s no closed-form solution at all for the integral! As an example, consider the Gaussian function, which shows up in the normal distribution. With zero mean and unit variance, it looks like this:
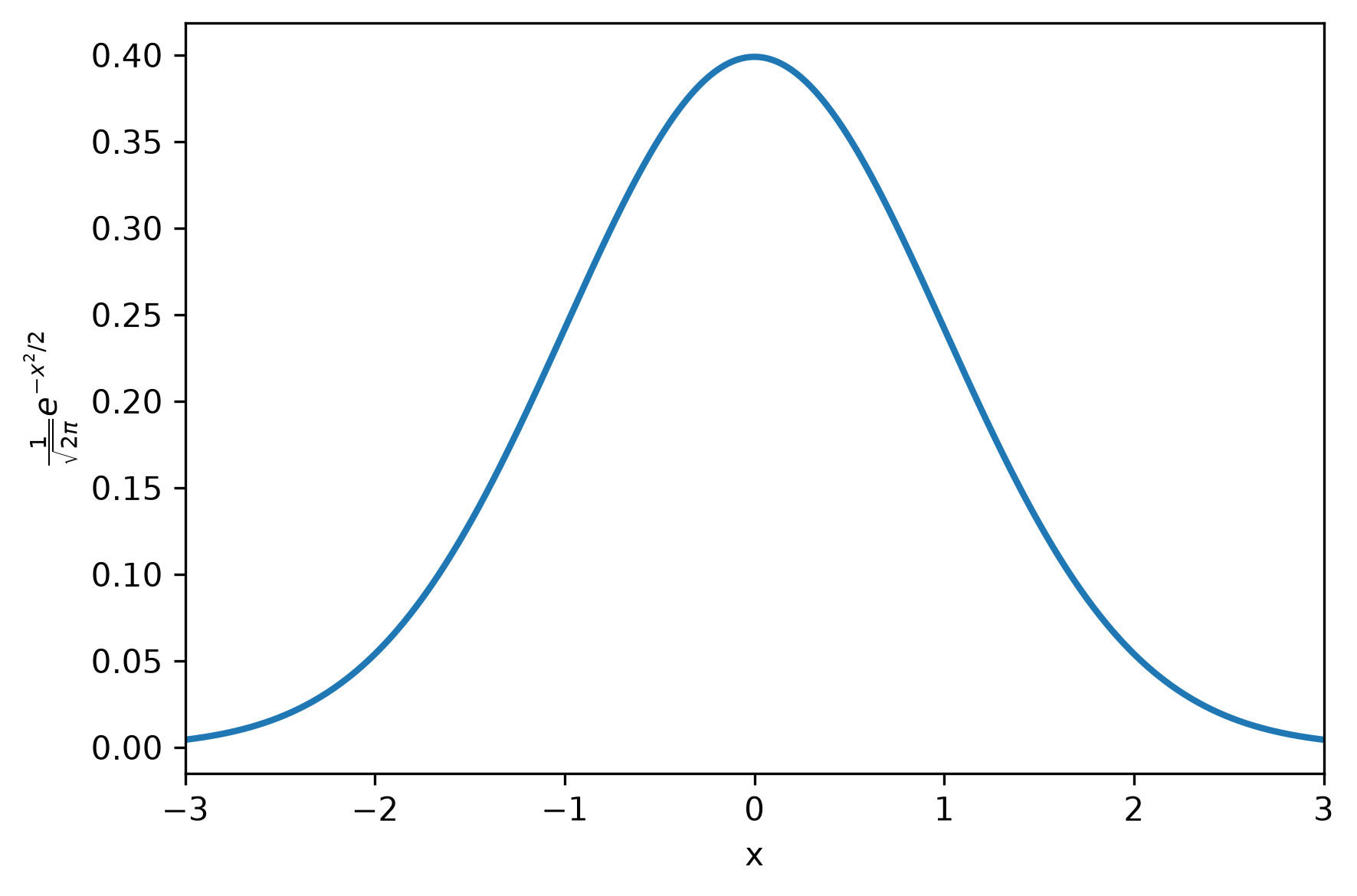
Asking students to compute the derivative of this function would be a perfectly reasonable question on a Cal 1 final exam, the answer looks like this:
But asking students to compute the integral of this function on a Cal 2 final exam would be unfair, because it’s not possible to do with the techniques they learned in class (at least, I didn’t learn the technique you’d need until Cal 3). Because the integral doesn’t have a closed-form solution, you need to express the solution as an infinite series, like:
(Note: I asked AI for the integral of the Gaussian, I hope it got it right!)
It’s not obvious (at least, not to me) that differential calculus and integral calculus are related to each other. However, it turns out that these two calculi are opposite sides of the same coin, because integrals are anti-derivatives. That is, if f(x) is the derivative of F(x), then F(x) is the integral of f(x). This result is known as the Fundamental Theorem of Calculus.
This connection between differential and integral calculus raises an almost philosophical question: why is it so much easier to compute a derivative than it is to compute an integral? Back in 2011, somebody asked about this on the Mathematics Stack Exchange: Why is integration so much harder than differentiation? The top-voted answer was written by Qiaochu Yuan, and here’s the heart of it (emphasis mine):
Differentiation is a “local” operation: to compute the derivative of a function at a point you only have to know how it behaves in a neighborhood of that point. But integration is a “global” operation: to compute the definite integral of a function in an interval you have to know how it behaves on the entire interval (and to compute the indefinite integral you have to know how it behaves on all intervals). That is a lot of information to summarize. Generally, local things are much easier than global things.
In one sense, local things are easier than global things is a banal statement. Everybody knows that, for example, local optimization is much easier than global optimization. But it’s also a very deep one. And it gets at the title of this post, which is synthesis is harder than analysis.
I previously wrote about the difference between analysis and synthesis in the demon of the gaps. In analysis, we’re breaking a larger problem into smaller problems that separate out cleanly. These smaller problems are more localized, and hence easier to solve. This is why we advocate for principles like encapsulation and separation of concerns, to ensure our smaller problems are local.
The work of synthesis involves integrating(!) multiple things together. This pushes in the other direction: we are creating a problem that is less local. And global things are much harder than local things. The challenge we face is that some kinds of problems are just inherently synthesis problems. As I wrote in that previous post, incident response is one area where we are frequently confronted with synthesis problems: we have to understand how the pieces normally fit together in order to make sense of what is currently going wrong.
That’s why I think that this sort of synthesis work is important for SREs. Now, because synthesis is harder than analysis, and because SREs don’t have super-human cognitive abilities, it means that there is a limit to how deeply they will be able to understand any given component in the system. But the more they understand how the different components interact, the better positioned they are for helping resolve the tougher incidents.
Unfortunately, in our industry we haven’t recognized building up synthesis expertise as a first-class thing. That’s understandable because this work is very situated, it depends on the messy details of the particular system in the organization that an SRE works in. On the other hand, we can get better at learning how to learn about the operational details of a system. And that’s what I’d like to see more of.
I am dreading our LLM-written incident report future
The other day, Reginald Braithwaite posted the following toot. For posterity, I’ve also included my own response to it:
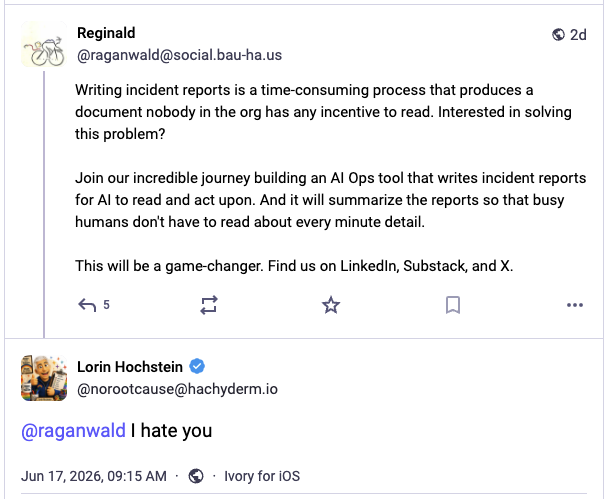
Braithwaite’s post is dripping with sarcasm, but make no mistake, incident reports written entirely by LLMs is coming. And I am not looking forward to this future.
Before I dive in here, I want to note that there is a lot of toil you need to do in order to gather the data you need to write a good incident report, and LLMs can help significantly reduce that toil. I’ve got no issues there. But there’s a world of difference between using LLMs to help you assemble the ingredients involved in writing an incident report, and using an LLM to actually write the report itself.
Braithwaite’s post is horrifying to me precisely because of the seduction of the LLM as a tool for generating an incident report. After all, you can just ask it to write the report, and it’ll do it. And that’s exactly what scares me.
There’s a famous quote by the cartoonist Dick Guindon: “Writing is Nature’s way of showing you how sloppy your thinking is“. You might think you understand a concept, but it’s only when you put metaphorical pen to paper, when you actually try to explain the concept in written words to a potential reader, that you realize how fuzzy your understanding actually is. Writing in your own words forces you to confront how much you actually understand what it is that you’re writing about. Or, as Leslie Lamport put it, “If you’re thinking without writing, you only think you’re thinking.”
Having an LLM generate the text of an incident write-up bypasses this thinking step. Now there’s no human in the loop of the writing process that has to confront whether the explanation is actually consistent with the evidence that they’ve gathered. Instead, what you get is a plausible explanation of what happened to someone who is not intimately familiar with the details. They might read, nod along, and think, “yes, that makes sense.” But the LLM may have invented couplings between systems that aren’t there, and may miss critical interactions that were actually part of the incident, and because nobody did the hard work of actually synthesizing the data to do the write-up, nobody will notice. Because if you’re trying to reduce the writing effort, how much effort are you really going to put into checking the LLMs work.
In my view, LLM-generated incident write-ups are more dangerous than using LLM for coding or for AI SRE style tasks. For coding tasks, there’s always a testing step to check that the code exhibits the desired behavior, even if nobody looks at the code itself for meaningful details. For AI SRE tasks, either the LLM output helps you resolve the incident, or it doesn’t. In both cases, Nature is the ultimate arbiter of the LLM output.
But incident write-ups aren’t like that. The consequences of a poor report aren’t immediately apparent the way incorrect code or an incorrect operational diagnosis are in the moment. Instead, we get incident reports that have the superficially correct form, but are actually incorrect, with no obvious test for correctness.
And, because incident reports are time-consuming to write, the temptation to use AI tools to generate them will be overwhelming. But these LLMs will not go around talking to people that were involved in the incident. These reports will be simulacra; they will have the right form, but they will not provide readers with genuine insights into the nature of the system. The amount of learning will be significantly curtailed.
And, yes, people will probably use AI to summarize them as well.
It’s not a future I’m looking forward to.
Dear researchers column
The Journal of System and Software publishes a regular column called Dear Researchers: The perspective of software practitioners. Each column is an open letter to the software engineering research community from someone who works in tech. It’s edited by Austin Henley and Olaf Zimmermann, both of whom have experience in the two worlds of academia and industry.
They invited me to submit a column, which I did. When it finally gets published, you’ll be able to find it here: Dear researchers: help me deal with incidents! The published version will eventually go behind the journal’s paywall, but here’s a preprint of the column that you can always read free of charge.
I can’t bear to read AI-generated prose
I can’t bring myself to read text if I believe it to be AI-generated.
Now, I ask LLMs questions all of the time, and I do read those answers. I frequently use tools like ChatGPT and Claude as replacements for Google for answering specific questions; that’s not what I’m talking about here. I’m also not talking about reading LLM-generated code. What I mean is, if I’m reading some sort of a document, if I suspect that the document was AI-generated, my motivation to read through it drops down to approximately zero. If I was browsing non-fiction books in a bookstore, and a book was marked as having been AI-generated, I wouldn’t pick it up.
Being honest with myself, I think this point of view is irrational. My personal primary goal for reading any sort of non-fiction document is to advance my understanding of a topic, or put new ideas into my head. In principle, it shouldn’t matter whether the words on the page were emerged from the thoughts of a human being or via an autoregressive stochastic process. In addition, I’m very far from being a perfect detector of AI-generated text, so there isn’t even a way for me to know whether a particular document I’m reading came from a human or a machine. Also, AI generation is a spectrum. No document is completely AI generated: they all start with a prompt was written by a human. Some texts will have been iteratively generated by a collaboration of human and AI. If I knew that an author had used AI as a copyeditor, or to tighten up some of their sentences, that wouldn’t bother me at all. There’s not some magical threshold in my head about how much AI assistance I would consider to be OK, nor would it ever be possible for me to know whether that threshold was exceeded unless the author explicitly told me.
And yet, despite knowing this, I’m just turned off by reading anything that strikes me as being AI-generated. If I’m asked to read a design document, and I suspect the doc was written by AI, I need to fight myself to actually get through it. I feel like a writer should always spend more time generating a document than a reader should spend consuming it, and asking me to spend more time on understanding something that someone else didn’t put the effort into writing feels like a violation of an implicit contract.
As I said, I think this is an irrational response. And I expect the quality of LLM writing to continue to improve over time, so that we stop referring to it as slop. But there’s just something, well, soulless about the idea of writing generated by a machine.
The demon of the gaps

Modern software systems contain within them a mind-boggling level of complexity. As software engineers, we make this complexity manageable through techniques like decomposition, information hiding, and abstraction. We endeavor to break our systems up into components that interact over well-defined interfaces. By doing this, the surface exposed to individual software engineers is dramatically reduced: no individual has to understand how the entire complex system works in order to contribute to their system. Instead, each software engineer needs to understand only the individual component that they work on, along with the interfaces of the other components that they interact with. Decomposition is synonymous with analysis, where you study a larger thing by breaking it up into smaller pieces that are more amenable to understanding.
You can see this strategy of complexity management in action in microservice architectures. An engineer needs to understand the service that their team owns, and the interfaces of the services that their team calls out to. This architecture effectively bounds the information that an engineer needs in order to work effectively. Microservice architectures aren’t there for scaling the software itself, they’re there for scaling the software organization.
Unfortunately, when the system breaks down, this complexity management strategy breaks down itself. Just as hurricanes don’t respect political boundaries, system failures don’t respect component boundaries. Yes, sometimes the problem in a software system is limited to the failure of a single component. Those are the easiest cases to diagnose and mitigate. However, the hairy incidents are the ones that arise due to unexpected interactions across components. Maybe you have several services that are throwing errors, or maybe none of the services are throwing errors but customers are still seeing incorrect behavior. There’s no obvious change that correlates with the start of impact, or maybe you don’t even know when the impact started because the customer impact isn’t reflected in your existing metrics.
When you’re in the throes of an incident that involves an unexpected interaction, this architecture that was built for managing complexity now works against you. Because you’ve built an analysis solution but you’re now faced with a synthesis problem. You need to understand how the pieces all normally fit together to function in order to determine what is going wrong with the system right now. You’ve optimized to avoid requiring anybody to understand how the whole thing works, but now the whole thing isn’t working, and no one person knows how the whole thing works.
The job of the incident responders is to collectively figure out how to do that synthesis. You’ve brought together a group of people who each understand the functions of different components of the system, and you need to work together to build enough of an understanding of how the system functions to debug what’s going wrong. As an ad hoc team, the incident responders have to move up and down the abstraction hierarchy to figure this out.
This sort of in-the-moment reconstruction of system function from component parts is an essential part of incident response for the most complex incidents, but it’s rarely treated as first-class work that’s worthy of study and support. The recent book Crisis Engineering by Marina Nitze, Matthew Weaver, and Mikey Dickerson is the exception that proves the rule: they do discuss the work of building a model of the system during a crisis to help figure out what’s gone wrong. But I struggle to recall any other guidance I’ve read about incident response that talks about how to prepare for doing this sort of work. It’s important work, and it’s difficult, and the ability to do it well can have a huge impact on the time it takes to mitigate the hardest incidents. This is stuff that even the best individual humans struggle with, because it involves a group of humans working together effectively, with each person having a partial model of the system. And if the best humans struggle with it, I don’t think AI SRE tools are going to save us here: if the best humans struggle, the AIs will too. We need to figure out how to get better at this collectively. Like so many things, it’s a coordination problem.
Form may follow function, but use doesn’t follow design
At this point, you have no doubt heard about GitHub’s availability woes over the past several months. In April, Mitchell Hashimoto (of Hashicorp fame) wrote a post about how he is moving his Ghostty project off of GitHub:
…for the past month I’ve kept a journal where I put an “X” next to every date where a GitHub outage has negatively impacted my ability to work. Almost every day has an X. On the day I am writing this post, I’ve been unable to do any PR review for ~2 hours because there is a GitHub Actions outage. This is no longer a place for serious work if it just blocks you out for hours per day, every day.
The irony here is that GitHub, a centralized service, is built on top of git, a version control system that was designed by Linus Torvalds to be fully decentralized. I can’t read Torvalds mind, but I’m pretty sure that GitHub was not what he had in mind when he was developing git to support Linux kernel development. Which, of course, brings us to the pope.
We are called to reflect on the great “construction sites” of our era and ask: What are we building? – Pope Leo XIV
Pope Leo XIV just released an encyclical, Magnifica Humanitas. Now, I don’t usually write on the topic of papal encyclicals, since this isn’t a blog about religion, and I’m not even Catholic. However, this particular encyclical discusses technology in general, and artificial intelligence in particular.
For this reason, technological progress — valuable in itself — requires careful discernment of the anthropological vision that guides it and the ends it pursues.
In this encyclical, the pope encourages us to be deliberate about the kinds of technological projects that we work on: rebuilding the walls of Jerusalem is good, but building the Tower of Babel is not. He writes about the dangers of a technocratic perspective that is focused solely on matters such as efficiency, control, and profit, and neglects humanistic ends. AI isn’t neutral, argues the pope, because technologies are never neutral. The technologies reflect values that were made by the designers, either explicitly or implicitly.
In reality, every technical tool embodies choices and priorities through what it measures, ignores and optimizes, and how it classifies people and situations.
I bring up the encyclical not to argue in support or in opposition to the content, but to bring up a point that is frequently neglected when these sorts of discussions of technologies come up. Designers of technologies are not particularly good at predicting how those technologies will actually be used. Could Linus Torvalds have predicted the role that git would have had played in enabling GitHub to become a centralized point of failure? Heck, could AI researchers have predicted the fantastic success of LLM-powered code generation tools like Claude Code? In a sense, the technologist is worst-positioned to predict the impact of technology, because the intended use is so fixed in their minds, they are unable to imagine how others might use their technology in different ways or for different purposes. If you’ve ever seen a UI designer observe a usability study of their own designs, and you’ve seen the shock on their face as the user behaves in unexpected ways, you’ve seen this in action.
We engineers are trained on how to build things, but we’re not trained on how to predict the effects of the things that we build. Now, there is some lip service paid to this: when I was an undergraduate engineering student at McGill University, I had to select a single humanities course to cover my impact of technology on society requirement (I chose religious ethics and the environment, which is still being taught). But, really, that’s just a single course.
I frequently write in this blog about how the technologies we work with are fundamentally unpredictable, which is why incidents are unavoidable. But it’s not my intent to be a fatalist here about coming to grips with the impact that a particular technology may have. Instead, what I want to argue is that studying the impact of technology requires an additional set of skills beyond the ability to design technology.
Here I’ll make a pitch for an engineering domain which specifically focuses on the impact of technology: cognitive systems engineering (CSE). CSE is a field that lives at the intersection of people, technology, and work. These are folks who study how the work is shaped and changed by new technology. John Allspaw just wrote a blog post about CSE over at Adaptive Capacity Labs: How is a Cognitive Systems Engineering perspective different from traditional UX/UI? I also maintain a bibliography of CSE papers if you’re interested in reading further.
The coming coordination calamity
We cut middle managers across the organization because AI allows us to have more direct reports per manager while still measuring and mentoring our teams effectively.
– Matthew Prince, How I Choose Which Cloudflare Employees to Replace With AI
My PhD research involved studying programmer productivity for a very specific domain: high-performance computing, more commonly known as supercomputers. It turns out that supercomputers are difficult to program, and so the U.S. government was interested in assessing the productivity impact of different software engineering technologies (in my case, parallel programming languages), which is how the research got funded.
Since supercomputers are built by connecting together many processors in parallel, you might think that cloud computing providers like AWS obviate the need for supercomputers. Why should a lab buy a very expensive supercomputer when it can just rent compute time from Amazon and get access to the same kind of resources? But what makes a supercomputer isn’t just the processors, it’s also the network interconnect. And that’s because supercomputers are used for problems that require a lot of coordination among processors. For example, consider the problem of simulating the Earth’s climate. The earth is modeled by carving it up into a grid. The grid is divided up among the processors, which each simulate some local part of the grid. But these processors need to exchange data at the grid boundaries, and that involves coordination.
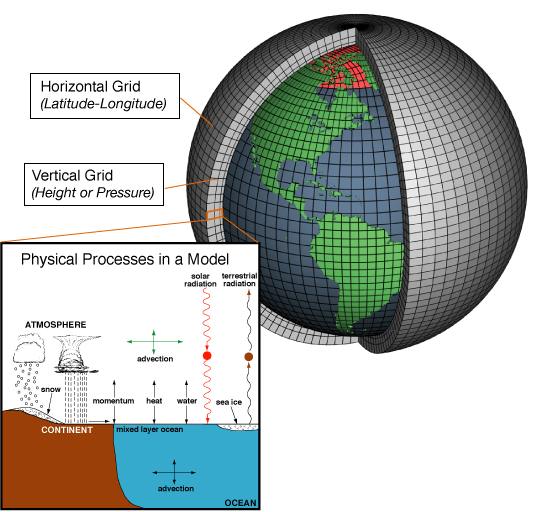
This type of coordination is expensive, because communicating over a network is much slower than communicating with local memory.
In general, as you scale up the number of workers, the coordination overhead increases. This is one of the reasons why we use thread pools rather than allowing an unbounded number of threads. If you keep spawning new threads, eventually the overhead that the operating system has to pay to maintain these threads exceeds the performance gains you get, and the extra threads actually hurt performance.
It’s well known that coordination costs increase with the number of agents involved in the system. This is why we spend more time in meetings in larger organizations, and why these organizations feel like they move so much slower than startups. Larger organizations have to pay the coordination cost of being larger.
With the rise of coding agents, our jobs as engineers is shifting from coding to managing these coding agents. We’re also not restricted to running a single agent, we can run multiple agents in parallel. By doing so, we can get more work done, since we’re not blocked waiting for one coding agent to complete its task. But now we’re not just managing a single agent, we’re coordinating the work of multiple agents. And, of course, we want to keep those agents busy doing useful work!
What this means is that we can expect that engineers will spend more of their time in the future doing coordination work among the agents that they manage. This is on top of the normal coordination work they do with other humans.
I opened this post with a quote from the CEO of Cloudflare, Matthew Prince, about reducing the number of managers in the company, and increasing the span of control of existing managers. They aren’t alone; Meta has also eliminating managers in their recent layoffs. Managers have always had to do coordination work, and as their span increases, they’ll have to do even more of that work. If they are expected to manage coding agents as well as humans, well, that’s yet more coordination work that will be poured on top of their existing load.
All of this new coordination effort represent a significant change in the day-to-day work of software engineering. And, take it from someone who does incident management: coordination is hard! I think this adjustment will be bumpier than people realize.
Reliability as a game of improving the odds
I’m a betting man; I just enjoy making bets, even when there are no stakes at all.
And when you talk about bets, you end up talking about odds.
It turns out that reliability is also about odds, even though we don’t use the language of odds in our domain. Consider how we talk about availability. We report system availability as a number of nines: for example, we might say “four nines of availability”, which means 99.99% of somethings are good over some time interval. The canonical example of those somethings are successful requests. In that case, if someone says a service has four nines of availability over the past three months, that means that 99.99% of requests succeeded over that time period. We could express the same information by saying that there is a one in ten-thousand chance that any given request failed in the past three months.
If your system has exhibited four nines of availability in the past three months, and you assume that the availability of your system in the near future will be like the availability of the past (a dangerous and unwarranted assumption, but let’s go with it for a moment), then we could also express this information using the language of odds, by stating that the odds of a request failing are ten-thousand to one.
But this isn’t a post about describing availability in the language of odds. Instead, what I want to talk about is how all reliability work is inherently about improving the odds, increasing the likelihood that the system stays up. Any time we build any sort of reliability mechanism, be it load shedding, autoscaling, canarying, staged deployments, automated rollbacks, or what have you, we are building automation into the system that either eliminates or reduces the impact a subset of potential problems. If you ask an engineer working on improving reliability, “will this prevent all future incidents”, they will tell you “no, of course not”.
However, we don’t explicitly think of reliability work in terms of improving the odds. Instead, we tend to think of it as deterministically addressing a specific class of problem. You’ll hear questions like, “how many historical incidents would this tech have prevented?” in trying to determine whether engineering should invest in a particular reliability solution. They are looking for an answer like, “this would have prevented 20% of our SEV1s and SEV0s”. This 20% isn’t interpreted as a likelihood, instead it’s used as an estimate of impact, as in “this will improve our availability by around 20%”. The idea is that this reliability work will deterministically eliminate or mitigate a certain fraction of incidents; we just don’t know exactly what that fraction is, so we estimate it from historical data.
What I would like to propose in this post is that we think about all of the various kinds of reliability work as improving the odds of our system being up longer, instead of assuming that reliability work will have a fixed effect, and try to estimate the effect size. I’ve got two motivations for taking this perspective of reliability work as odds improvement.
The first motivation is that I don’t think we can ever estimate the effect size without error bars that are so huge that the estimates are themselves meaningless. As I’ve written about previously, the variation in incidents is just too large relative to the amount of data we have available. And, to make the estimation problem from historical data even worse, our system is changing over time. Or, to put it in technical terms, I don’t believe that incidents can be modeled as a stationary process. (Heck, if they were stationary, then that means that reliability work could not have an impact, because then the process would change over time!). Note that I’ve never seen anybody try to validate the estimates, they’re always point-in-time estimates used to justify work, and then promptly forgotten about. In one sense, that’s fine, they served their purpose of convincing leadership that we should allocate cycles for a particular kind of reliability work. But we shouldn’t fool ourselves into believing that these estimates are meaningful: they’re for persuasion, not insight.
It’s my second motivation, though, that prompted me to write this blog post. And that’s because the idea of reliability work as improving the odds of effectively mitigating future incidents is a useful framework for thinking about work that improves resilience. I’m interested in improving the skills of the people who respond to incidents, putting them in a better position to deal with those future unforeseen, surprising scenarios. One way to do this is learning from how responders dealt with previous incidents, the different sorts of observability data they had access to and how, the different knobs that were able to turn, and so on. While the next incidents will be different, the set of tools that are available during incident response are generally the same. There’s no way I can give a quantitative of estimate how this sort of skill improvement work will impact reliability. And despite the enormous number of random factors, I am confident that it will improve our odds.
Flipping the bozo bit on flips the learning off

“Flipping the bozo bit” is an expression from the software world. Think about a time when you reached a point where you simply stopped respecting the opinion of a particular person, most likely a co-worker. From that point on, you disregarded what they said. This is what flipping the bozo bit is. This person isn’t worth listening to, they’re a bozo.
There’s a related phenomenon, where we hear an anecdote about some bad outcome that happened to someone else, and our conclusion is that this outcome occurred because, well, that person is a bozo. I’m writing, of course, about incidents. You’ve seen this happen, right? An incident happens, the details of the incident get passed around, and somebody makes a comment like, “how could they have [not] done X?” The subtext is “what a bunch of bozos!”
This is on my mind because of the latest AI-related incident that befell PocketOS. You can read about it in the Twitter post written by the PocketOS founder, Jer Crane. The post is titled An AI Agent Just Destroyed Our Production Data. It Confessed in Writing. Unsurprisingly, this post got a lot of online attention. I saw a lot of “wow, was this guy ever a bozo” reactions to this story. I want to talk about why this reaction is counter-productive. I also want to call out the technical term for this phenomenon, which is a cousin of flipping the bozo bit. It’s called distancing through differencing.
The term distancing through differencing was introduced by the American resilience engineering researchers Richard Cook and David Woods in their 2006 paper: Distancing Through Differencing: An Obstacle to Organizational Learning Following Accidents. Technically, it’s a book chapter, from Resilience Engineering: Concepts and Precepts. It’s very readable, and I recommend it. All of the quoted text below is from that paper.
By focusing on the differences, they see no lessons for their own operation and practices.
When people hear about an incident and respond by concluding “an incident like that would never happen to us; that happened to those workers over there because they are clearly not as careful as we are, that’s distancing through differencing in action.
Overall they decided the incident “couldn’t happen here”.
The Cook and Woods paper illustrates the phenomenon with a case study of a chemical fire that broke out at an American manufacturing plant. There had been a similar fire that had occurred previously at the same company, at an overseas plant. The American employees knew about the previous fire, but they had concluded that there was nothing to learn from that other fire, as that sort of accident couldn’t happen to them in the U.S. After all, those overseas workers were less skilled, less motivated, and less careful. In short, those overseas workers were perceived as different.
Ironically, after the chemical fire at the Ameircan plant, other workers at that very same plant also exhibited distancing through differencing.
Workers in the same plant, working in the same area in which the fire occurred but on a different shift, attributed the fire to lower skills of the workers on the other shift.
Cook and Woods note that our tendency to focus on differences between us and them when the incident happens to them leads us to miss aspects of the system that we actually have in common with them. By focusing on the differences, we miss the opportunity to learn from their experiences, because it seduces us into believing there’s nothing for us to learn here.
do not discard other events because they appear on the surface to be dissimilar. At some level of analysis, all events are unique; while at other levels of analysis, they reveal common patterns.
Now let’s circle back to the PocketOS AI-related incident. If we come to the conclusion that PocketOS employees were simply using AI irresponsibly, and that we are more responsible than that, we learn nothing from the experience. I was heartened to see that Railway, the vendor used by PocketOS that exposed the delete API, has made changes to the overall system to improve safety; see their post: Your AI wants to nuke your database. Guardrails fix that.
Stepping back, this isn’t the last AI-related incident we’re going to see in our industry, not by a long shot. The next time you read one of those, if your reaction is “they should have known not to do X”, then you’ve fallen into the distancing through differencing trap.
(As an aside, “they should have known…” is an incoherent sentence. It’s one thing if somebody deliberately took on excessive risk. But it’s another thing if they unknowingly took on excessive risk. How can you blame a person for not knowing something?)
When this process of learning moved past the obstacle of distancing through differencing in this case, the organizational response changed.
After all, there but for the grace of God go we all.

{kind=link}
{kind=link}